The adoption of high-value yet high-impact technologies such as AI and cloud should always follow a roadmap aligned with the organization’s maturity level and operational context.
It is essential that decision-makers have a clear vision and motivation to ensure the successful introduction of new technologies.
Forward-thinking organizations should also consider the post-adoption phase—what happens after achieving an initial goal, which in most cases will be intermediate or exploratory in a first adoption phase.
A consolidation phase should be planned, where service adjustments identified during the adoption phase, but not initially foreseen, can be implemented.
Simultaneously, expansion or evolution phases can be considered.
In the case of cloud, it is now common to think in terms of consolidation or expansion phases. However, in some cases where expected results are not met (NOT OK), cloud services may even be decommissioned.
In contrast, AI adoption is still in an early stage for many organizations, with some in a standby phase, waiting to observe results from other experiences.
Table of Contents
Cloud Adoption – Driving Digital Transformation with Strategies and Innovation
The Cloud Adoption Process.
Cloud adoption typically unfolds in three phases.
The first phase is the actual adoption, where the organization defines objectives for which the cloud is deemed central. The motivations behind a cloud adoption project can vary widely experimental, tactical, or part of a long-term strategy.2
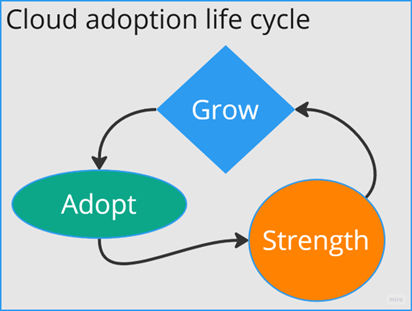
The key factor determining the success of the adoption phase is the realistic definition of expected outcomes.
This success factor is strongly influenced by the organization’s posture toward the adoption project. Has the company already gained experience at the technical, administrative, and managerial levels?
This, in turn, depends on the organization’s cloud maturity level and its awareness that cloud requires a different service model from traditional IT.
A sensible approach to cloud adoption involves clear goal setting. If your primary objective is cost reduction, you have chosen the most challenging goal—sometimes even unfeasible within a cloud adoption process.
If this is your goal, there are only two possibilities: either you have been using a well-configured cloud-native information ecosystem for some time, or you have little experience with cloud.
To properly assess cloud adoption, organizations should answer five key questions:
• Why?
• What?
• Who?
• When?
• Where?
Each response must be precise and well-defined.
Cloud adoption should not be seen as a strategy in itself but rather as a tactical step that becomes strategic over time.
Consider the analogy of home renovation. If you decide to renovate your entire home inside and out, you may need to temporarily live elsewhere while the construction takes place, ensuring that work follows the agreed-upon project plan.
For most organizations, such a scenario is impractical.
Instead, cloud adoption is more akin to renovating one room at a time—accepting temporary inconveniences such as noise, dust, interruptions, and the presence of external workers in the house.
The transition from an on-premises to a cloud ecosystem is similar: careful planning and incremental changes ensure a smoother process and a better final outcome.
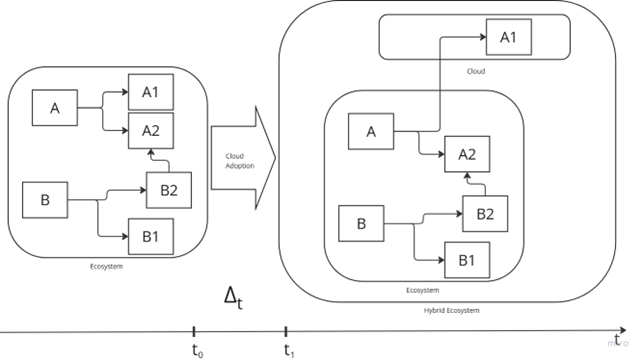
Cloud adoption reshapes the ecosystem: applications migrate to the cloud, evolving traditional architectures into hybrid ecosystems.
In Figure a highly schematic representation illustrates the state transition of an ecosystem due to cloud adoption.
At time t0, the ecosystem operates in a traditional configuration, executing two processes, A and B. Each process relies on specific services:
- Process A utilizes services A1 and A2.
- Process B utilizes services B1 and B2.
Process B was introduced after process A, and service B1 has a functional and operational dependency on service A1 (e.g., data flows, APIs, functions, or other dependencies).
For specific business or technical reasons, the decision is made to migrate service A1 to the cloud.
By the end of the adoption process, at time t1, the final ecosystem has transitioned into a hybrid model, where A1 now resides in the cloud.
But what happened to the ecosystem during the phase represented by?
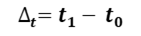
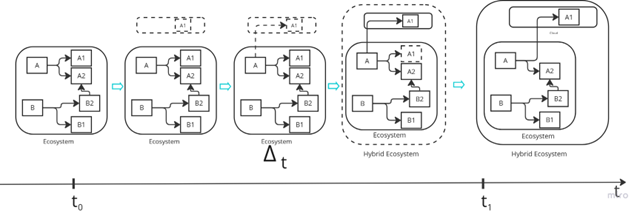
The transformation phase of cloud adoption: applications gradually migrate, reshaping the ecosystem into a hybrid model over time.m.
In Figure the cloud adoption process is depicted through key milestones, capturing the ecosystem’s transformation.
If, instead of A1, service A2 were migrated first, the complexity of the adoption process would increase significantly.
Service A2 has multiple dependencies. Moving it first would extend the adoption timeline due to the additional integrations required between cloud-based and on-premises components.
Interestingly, in real-world scenarios, organizations often face the challenge of migrating A2 rather than A1. Core services like A2 are frequently used by multiple other services and may need to be made accessible to cloud-based services already in place.
A common example is a data warehouse, a data mart, or a dataset generated from a complex SQL view or procedure executed in real-time.
Typically, the more valuable the data, the more it becomes entangled within multiple application layers, incoming and outgoing data flows, and business logic layers.
Older hosting technologies tend to accumulate these layers over time, making migration increasingly complex.
Not all cases follow this pattern, but in many situations, organizations prioritize immediate cost and time savings, leading to layered and entangled legacy systems.
If an organization lacks cloud maturity and experience, it is advisable to start with peripheral scenarios before tackling core components.
However, budget constraints often mean that smaller, peripheral projects receive less funding, limiting their ability to serve as meaningful test cases.
Eventually, the need arises for data and services to be shared across the organization. This is where different cloud adoption scenarios emerge, which we will explore in the next chapter.
A recommended best practice is to include one or two low-risk migration projects (such as A1) in the early phases of a larger cloud adoption initiative. This allows organizations to gain experience and refine their migration process before addressing more complex cases.
The Next Phase After Cloud Adoption: Consolidation
After the adoption phase, if the process has been successful, the organization enters the consolidation phase. Around the newly implemented cloud ecosystem, service extensions begin to emerge, generally aimed at improving efficiency, optimizing costs, and enhancing overall effectiveness.
A service built in the cloud has a smoother evolution: if designed with a cloud-native approach, it will be easier to extend and enhance over time.
If this phase also yields satisfactory results, the next step is expansion.
At this point, the organization may embark on a full-fledged race towards the cloud, often accompanied—or even preceded—by the adoption of artificial intelligence. This dynamic is reminiscent of the gold rush in the American West: exciting, full of opportunities, but also highly delicate from an IT and FinOps perspective.
In this phase, the cloud-native ecosystem may evolve into a hybrid or multi-cloud model, a scenario that, while representing a natural evolution, introduces new risks and complexities.
The initial core of the cloud ecosystem expands with new resource clusters, designed to meet emerging business needs. At the same time, other business areas begin exploring the cloud, creating additional resource clusters. In these early stages, each cluster typically consists of only a few dozen resources, allocated according to the operational needs of each process.
This is the moment when an organization can take a strategic step and decide to migrate entire business processes to the cloud ecosystem, firmly establishing cloud adoption. However, managing expansion across multiple business lines requires a high level of cloud maturity and a strong grasp of the FinOps framework to maintain cost control and ensure operational sustainability.
In general, the cloud adoption journey can be classified as either digital transformation or innovation, depending on the nature of the business being migrated.
A Special Case: Cloud-Specialized Services
For years, marketing and communication departments have been using tools such as Google Analytics. For these users, extending their infrastructure with a service like BigQuery is a natural step, often quickly leading to integration with Google’s Gemini AI. Once inside this ecosystem, alternatives become increasingly limited, and the trajectory of technological evolution is, in practice, guided by the service provider.ding 2
Cloud Adoption Models
Cloud adoption strategies can be classified into different categories, each describing how organizations migrate or adopt applications and infrastructure in the cloud.
There are various ways to represent these models, and the following classification does not claim to be exhaustive or definitive for all possible cloud adoption strategies (or tactics).
Rehost (Lift and Shift)
The Rehost strategy involves migrating existing applications and infrastructure to the cloud without significantly modifying their architecture. This approach is quick and allows resources to be moved from on-premises data centers to the cloud with minimal changes.
Operational Example:
- Moving a legacy application to a virtual machine on AWS EC2 or Azure VM without altering its code.
Advantages:
- Fast migration times.
- Low initial complexity.
Disadvantages:
- Limited efficiency gains.
- Higher operational costs.
- Does not fully leverage cloud-native capabilities like auto-scaling and managed services.
Refactor (Replatform)
The Refactor or Replatform strategy involves optimizing or modifying parts of an application to better leverage cloud services, without fully rewriting it. Minor changes to the code or infrastructure can improve efficiency and scalability.
Operational Example:
- Migrating an application to a managed database service like Amazon RDS or Azure SQL, eliminating the need for on-premises database management.
Advantages:
- Improved performance and scalability.
- Lower operational costs compared to Rehost.
- No need for a complete rewrite.
Disadvantages:
- More complex than Rehost.
- Requires additional effort for adaptation.
Repurchase (Drop and Shop)
With the Repurchase strategy, an organization replaces its legacy applications with ready-to-use SaaS (Software as a Service) solutions. This means abandoning existing infrastructure and directly adopting cloud-native solutions.
Operational Example:
- Replacing an internal CRM system with a SaaS solution like Salesforce.
Advantages:
- Significant reduction in management and maintenance costs.
- Immediate access to modern solutions with automatic updates.
Disadvantages:
- Loss of customization and control over the application.
- Data migration challenges.
Rebuild (Re-architect)
The Rebuild strategy involves completely rewriting an application to fully exploit cloud-native capabilities. This approach allows rethinking architecture using microservices, containers, and serverless technologies.
Operational Example:
- Transforming a monolithic application into a microservices-based architecture deployed on Kubernetes (EKS/AKS) or using AWS Lambda serverless functions.
Advantages:
- Maximum benefit from cloud scalability, flexibility, and resilience.
- Complete modernization of the application.
Disadvantages:
- Long and costly development process.
- Requires specialized skills and significant resources.
Retire
With the Retire strategy, an organization decommissions or removes obsolete applications or infrastructure. Sometimes, during migration planning, certain applications are found to be redundant and can be eliminated.
Operational Example:
- Decommissioning an old application that is no longer in use or has been replaced by a more efficient solution.
Advantages:
- Cost reduction from eliminating maintenance of unused systems.
- Simplification of the IT landscape.
Disadvantages:
- Possible resistance from teams still relying on the retired application.
- Potential loss of historical data.
Retain (Hybrid)
The Retain strategy involves keeping certain applications or data on-premises due to security, compliance, or operational dependencies on legacy systems. Organizations adopting this approach often manage a hybrid infrastructure, using both cloud and on-premises resources.
Operational Example:
- Keeping an ERP system on-premises while migrating fewer sensitive applications to the cloud.
Advantages:
- Flexibility in maintaining critical applications on-premises.
- Compliance with security and regulatory requirements.
Disadvantages:
- Increased management complexity.
- Higher operational costs.
- Challenges in integrating cloud and on-premises data.
New Application (Cloud-native Development)
With this strategy, new applications are developed directly in the cloud, following a cloud-native approach from the start. This model takes full advantage of PaaS (Platform as a Service) and SaaS capabilities.
Operational Example:
- Building a new application using AWS Lambda, DynamoDB, and S3, eliminating the need for physical servers.
Advantages:
- Maximum flexibility and scalability.
- Optimal use of modern cloud technologies.
Disadvantages:
- Requires cloud-native development expertise.
- High initial investment in development.
Evaluating Cloud Adoption Strategies: Benefits and Risks
These strategies allow organizations to gradually adopt the cloud according to their operational and technological needs. Each approach has its benefits and challenges, and the choice depends on factors such as cost, complexity, internal expertise, and business objectives.
Each cloud adoption strategy presents distinct benefits and risks. The selection depends on an organization’s specific needs, technological maturity, regulatory constraints, and balance between initial costs and long-term benefits. Companies must carefully evaluate which strategy to adopt based on their priorities, capabilities, and business goals.
Table – Analysis of Benefits and Risks for Cloud Adoption Strategies
| Strategy | Benefits | Risks |
| Rehosting (Lift and Shift) | Fast migration, Low initial costs, Simple implementation | Limited efficiency, Higher operational costs, Limited cloud benefits |
| Refactoring (Replatform) | Optimized performance, Lower operational costs, Improved scalability | Longer migration times, Higher initial investment, Need for new skills |
| Buyback (Drop and Shop) | Simplified complexity, Automatic updates, Predictable costs | Loss of customization, Training costs, Vendor lock-in risk |
| Rebuild (Redesign) | Full cloud benefits, Improved performance, High scalability | High initial costs, Operational risks, long implementation times |
| Retire | Cost savings, Simplified infrastructure, Increased focus on core services | Loss of historical data, Resistance to change, Potential operational impact |
| Retain (hybrid) | Flexibility, Security and compliance, Control over sensitive data | Increased complexity, Higher costs, Data integration challenges |
| New application (cloud-native development) | Maximizes cloud advantages, Accelerated innovation, DevOps compatibility | Limited efficiency, Higher operational costs, Limited cloud benefits |
Success Cases for Different Cloud Adoption Scenarios
Below are some publicly known success stories, each representing a specific cloud adoption strategy on a particular cloud provider.
Rehost (Lift and Shift) – Netflix (AWS)
Netflix initially migrated its on-premises infrastructure to AWS using a lift-and-shift approach, moving applications without significant modifications. This transition allowed Netflix to enhance scalability and disaster recovery while reducing operational overhead. Over time, Netflix evolved its architecture to leverage more cloud-native services, but the initial move provided the foundation for its current highly resilient, global streaming platform
See more on https://aws.amazon.com/solutions/case-studies/netflix/
.
Refactor (Replatform) – Coca-Cola (Google Cloud)
Coca-Cola leveraged Google Cloud’s Kubernetes Engine (GKE) to refactor and optimize its vending machine order management system. By migrating its microservices architecture to a managed Kubernetes environment, Coca-Cola improved service reliability, enhanced real-time analytics, and achieved better cost efficiency through auto-scaling and optimized infrastructure usage.
See more on https://cloud.google.com/customers/coca-cola
Repurchase (Drop and Shop) – Royal Dutch Shell (Microsoft Azure)
hell opted for a SaaS-based approach by transitioning its legacy ERP systems to Microsoft Dynamics 365. This move eliminated the need for complex on-premises infrastructure management, providing Shell with a more agile and integrated business platform that supports predictive analytics, automation, and streamlined global operations.
See more on https://customers.microsoft.com/en-us/story/royaldutchshell-energy-azure-dynamics365
Rebuild (Re-architect) – Capital One (AWS)
Capital One undertook a full application re-architecture by adopting microservices, serverless computing, and AI-driven automation on AWS. The company replaced monolithic banking applications with cloud-native services utilizing AWS Lambda, Amazon DynamoDB, and Amazon SageMaker for AI-driven fraud detection. This strategy resulted in improved security, better operational efficiency, and enhanced customer experience.
See more on https://aws.amazon.com/solutions/case-studies/capital-one
Retire – Dropbox (AWS to private Infrastructure)
Dropbox originally hosted its storage services on AWS but later decided to decommission parts of its cloud-based infrastructure in favor of an in-house solution called Magic Pocket. This transition allowed Dropbox to optimize its storage architecture, reduce dependency on third-party providers, and significantly cut operational costs while maintaining high-performance scalability.
See more on https://www.wired.com/2016/03/epic-story-dropboxs-exodus-amazon-cloud-empire/
Retain (Hybrid) – Volkswagen (Microsoft Azure + on-premises)
Volkswagen adopted a hybrid cloud strategy by keeping critical manufacturing and vehicle telemetry data on-premises while shifting other workloads to Microsoft Azure. This approach enabled Volkswagen to comply with strict data sovereignty regulations while taking advantage of Azure’s AI and analytics services for predictive maintenance, supply chain optimization, and autonomous vehicle development.
See more on https://customers.microsoft.com/en-us/story/volkswagen-groupmanufacturing-azure
New Application (Cloud-native Development) – Airbnb (AWS)
Airbnb was built from the ground up as a cloud-native platform using AWS services. By leveraging AWS EC2 for compute, Amazon RDS for database management, and Amazon S3 for storage, Airbnb ensured high scalability and global availability. Over time, it integrated AI and big data analytics to optimize search, pricing strategies, and fraud detection, making its infrastructure a benchmark for digital platform scalability and efficiency.
See more on https://aws.amazon.com/solutions/case-studies/airbnb
Conclusion
Cloud adoption is not a one-size-fits-all journey but rather a progressive transformation shaped by each organization’s context, priorities, and maturity. The strategies explored — from rehosting to cloud-native development — highlight that every choice carries both opportunities and trade-offs. Success depends less on the technology itself and more on the clarity of vision, the ability to balance risks and benefits, and the willingness to foster cultural and organizational change.
Adopting the cloud means embracing new operating models, strengthening governance and compliance, and developing the skills needed to manage complexity. Organizations that approach this transformation holistically — considering people, processes, and technology together — are better equipped to unlock the full potential of the cloud.
Ultimately, cloud adoption is not an end point but a continuous journey. As ecosystems evolve, hybrid and multi-cloud models will become increasingly common, enabling flexibility, resilience, and innovation at scale. By aligning strategy with execution, and innovation with responsibility, organizations can transform cloud adoption from a technical migration into a true driver of digital transformation.
References
This article is an excerpt from the book
Cloud-Native Ecosystems
A Living Link — Technology, Organization, and Innovation