
This is a wide post for a good read experience use a tablet, large smartphone or pc
Table of Contents
The Encoding Of Data
The word data (or its plural data points) is also one of the most frequently used terms in IT jargon, sometimes to the point of losing its true meaning and occasionally taking on an almost “romanticized” interpretation, often distant from reality.
A cloud-native ecosystem is built around the data lifecycle.
Let’s start with the basics, starting from a robust definition following then what’s mean data encoding until to get a first look on a data Lakes scenario.
Definition of the “data” in a cloud native ecosystem
The most general definition of the word data, in the context of the cloud and particularly within an informational ecosystem, is as follows:
Any recorded information used to describe events, objects, or entities, which can be collected, stored, processed, and shared to support decision-making, operational, or analytical processes.
The way data is managed within an informational ecosystem defines its quality, form, and security.
This leads to a discussion of the data lifecycle, which is integrated into the lifecycle of the informational ecosystem.
As we will see later in the book, the operations related to managing the lifecycle of an informational ecosystem, implemented through the DevOps framework, also encompass the data lifecycle.
The simplest way to represent data is tied to its possible representation in the physical world, particularly within the electronic circuits of our motherboards.
Let us attempt to provide a basic representation of data at the physical level. Experts in the field are kindly asked to bear with this extreme simplification.
Data can be said to be represented by an electrical voltage in a specific electronic component within a circuit, called a transistor.
At a given moment, if a voltage (measured in volts) is present across the transistor, the value of the data is considered to be 1; in the absence of voltage, it is considered 0.
In reality, this process is much more complex, but for our purposes, this simplification suffices.
At its most basic physical and electronic level, data can assume only two values: 0 or 1.
The basic unit of digital information is called a bit.
A bit can assume only two values, typically represented as 0 or 1, which correspond to two distinct states, such as on/off or true/false, within the binary system used by computers.
Now, for those willing to follow along, we will attempt to understand how the entire description of our world can be based on just two values: 1 and 0.
The Encoding of Data
The definitions of “bit” and “byte” originated around the mid-20th century.
The term bit, short for “binary digit,” was coined in 1948 by mathematician and engineer Claude Shannon, considered the father of information theory. Shannon introduced the concept in his famous paper “A Mathematical Theory of Communication” (a must-read), describing how information could be represented and manipulated using sequences of bits, or binary digits (0 and 1).
The term byte was coined by Werner Buchholz in 1956 during the development of the IBM 7030 Stretch computer. Initially, a byte represented a variable group of bits, but it was later standardized as a sequence of 8 bits. The byte thus became the basic unit of information storage in modern computer systems.
To better understand what a data unit represented by bits and an archive containing them might look like, imagine a household chest of drawers used for storing clothing—a compact and practical solution.
In one drawer, you might store socks; in another, undergarments; and in yet another, scarves, and so forth.
The Simplest Form of Data: The Bit
The simplest form of data is the bit. A bit can take only two values: 0 or 1.
If you wanted to represent four types of clothing, you could decide to encode them using two bits. Placing two bits side by side, each of which can assume two values, yields four possible combinations:
- 00
- 01
- 10
- 11
To these four combinations, you could assign specific meanings, such as types of clothing:
- 00: Socks
- 01: Undergarments
- 10: Scarves
- 11: Shirts
With this, you can encode the type of clothing—that is, the type of data—but you still lack information about quantity or position.
Representing Quantity
To include quantity, you could align additional bits, deciding that their combination of 0 and 1 represents a numerical value. You would need to establish a calculation rule or standard so that whoever writes or reads the data interprets the value consistently.
For instance, you might define a standard using a table:
Table 1 – A bit coding standard
| Bit 1 | Bit 2 | Bit 3 | Bit 4 | Valore |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 | 2 |
| 1 | 1 | 1 | 0 | 3 |
With four bits, you can achieve 2⁴ = 16 possible combinations, allowing you to assign 16 different meanings.
One widely used standard over time is represented in the following table:
Table 2 – Binary encoding as a power of 2
| Valore | Bit 1 | Bit 2 | Bit 3 | Bit 4 |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 1 |
| 2 | 0 | 0 | 1 | 0 |
| 3 | 0 | 0 | 1 | 1 |
| 4 | 0 | 1 | 0 | 0 |
| 5 | 0 | 1 | 0 | 1 |
| 6 | 0 | 1 | 1 | 0 |
| 7 | 0 | 1 | 1 | 1 |
| 8 | 1 | 0 | 0 | 0 |
| 9 | 1 | 0 | 0 | 1 |
| 10 | 1 | 0 | 1 | 0 |
| 11 | 1 | 0 | 1 | 1 |
| 12 | 1 | 1 | 0 | 0 |
| 13 | 1 | 1 | 0 | 1 |
| 14 | 1 | 1 | 1 | 0 |
| 15 | 1 | 1 | 1 | 1 |
By carefully interpreting the table, you can assert that the bit in the leftmost column is the most significant bit (MSB) because changing its value significantly alters the overall number.
Conversely, the rightmost bit is the least significant bit (LSB) because altering its value changes the overall number only slightly.
This binary numeric encoding has been used in computers since the first practical application of the Von Neumann cycle.
Combining Standards for Comprehensive Representation
Returning to our chest of drawers, suppose you want to indicate both the type and quantity of clothing. By adding another four bits, as in the numeric encoding table, you can represent up to 15 items for each type of clothing.
For example:
110011 means 4 shirts (11 = shirts, 0011 = 4).
Expanding further, you can also add the location of the items. Imagine the chest has four drawers, each represented by two bits:
| Bits | Drawer |
|---|---|
| 00 | First |
| 01 | Second |
| 10 | Third |
| 11 | Fourth |
Now, the first two bits of your sequence encode the drawer:
01110011 means 4 shirts in the third drawer (01 = third drawer, 110011 = 4 shirts).
Now let’s also add the location of my clothing. Let’s imagine the chest of drawers has four levels, each with a single drawer. At this point, I know I can use two bits to encode the levels.
As before, I need to establish a shared standard with you:
00: First level
01: Second level
10: Third level
11: Fourth levelI decide to include the level as the first two bits of the previous sequence, resulting in something like the following:
01110011
10001100
00010101
11101011On which level are my four shirts?

A chest of drawers (with socks) invented by Old (ChatGPT Dall-e)
First Protocol about data
The first widely recognized protocol for data communication is the Telegraphy Code, which laid the groundwork for encoding and transmitting information.
However, when we refer specifically to the modern era of digital data, the Transmission Control Protocol (TCP) and Internet Protocol (IP) stand out as foundational elements.
Early Data Communication Standards
- Morse Code (1837):
- Developed by Samuel Morse, it was one of the earliest methods to encode and transmit data as sequences of dots and dashes over telegraph systems.
- While not a protocol in the modern sense, it established the concept of encoding information for transmission.
- Baudot Code (1870):
- Created by Émile Baudot, this telegraphy code was a more advanced system for encoding text into binary-like sequences of signals.
- It represents an early attempt at creating standardized data representation.
The Rise of Modern Protocols
- ASCII (American Standard Code for Information Interchange, 1963):
- Developed as a character encoding standard for text, allowing different systems to communicate text data reliably.
- ARPANET’s NCP (Network Control Protocol, 1970s):
- Predecessor to TCP/IP, NCP was the first protocol suite used to manage data communication on ARPANET, the forerunner of the modern internet.
- TCP/IP (1980s):
- Transmission Control Protocol (TCP): Ensures reliable data transmission by managing packet sequencing, error correction, and acknowledgments.
- Internet Protocol (IP): Governs the routing of data packets across networks.
- Together, TCP/IP became the backbone of modern data exchange, enabling the internet to flourish
Key Contributions of TCP/IP:
- Standardization: Provided a universal framework for data transmission across heterogeneous systems.
- Scalability: Supported the rapid growth of interconnected networks.
- Interoperability: Allowed devices from different manufacturers to communicate seamlessly.
Significance Today
The first protocols, while rudimentary, laid the conceptual foundation for modern data communication.
Today, TCP/IP and its derivatives (like HTTP, FTP, and DNS) remain essential for data exchange in the cloud, IoT, and AI ecosystems.
These protocols demonstrate how early innovations continue to influence the digital infrastructure of the modern world.
The screen from which you are reading this document uses a highly sophisticated encoding system based on standards in which the data stream stored in an archive is transmitted in sequences of bits to the screen. The screen translates this stream into an interpretative form suitable for the human eye and brain. These could be characters, still images, or sequences of images; they are all sequences of bits.
It is clear that those who store the data and those who represent the data must use the same standard, which in this case is called a protocol.
Similarly, data storage from my mind as I write to the computer happens using a tool—the keyboard—that interprets the key I press and transforms it into a sequence of bits. The same operation is performed by your smartphone’s camera, albeit with a different protocol.
The fact remains that all this implies two things: data is transferred, and during the transfer, a common protocol must be defined among the writer, the storage medium, and the reader.
For example, “This sentence translated into bits would become:”
01010100 01101000 01101001 01110011 00100000 01110011 01100101 01101110 01110100 01100101 01101110 01100011 01100101 00100000 01110100 01110010 01100001 01101110 01110011 01101100 01100001 01110100 01100101 01100100 00100000 01101001 01101110 01110100 01101111 00100000 01100010 01101001 01110100 01110011 00100000 01110111 01101111 01110101 01101100 01100100 00100000 01100010 01100101 01100011 01101111In the box, the binary code representation includes additional spaces between sequences to make it more interpretable and comparable with the words of the sentence.
As a pure sequence of bits, it becomes:
010101000110100001101001011100110010000001110011011001010110111001110100011001010110111001100011011001010010000001110100011100100110000101101110011100110110110001100001011101000110010101100100001000000110100101101110011101000110111100100000011000100110100101110100011100110010000001110111011011.The translation was carried out using an international standard based on the ASCII format (American Standard Code for Information Interchange).
In modern systems, storing and transmitting data requires shared standards to interpret electrical signals that encode binary data. Your display, for instance, converts stored binary sequences into visual content, such as text or images, using specific protocols.
The ASCII (American Standard Code for Information Interchange) standard is one such example, where each character corresponds to a unique 8-bit or 16-bit code. Similarly, Unicode extends this to support characters from multiple languages and symbols, using up to 32 bits per character.
These standards form the backbone of how data is encoded, stored, transmitted, and represented across digital systems, enabling seamless communication and functionality in modern ecosystems.
The Weight of Data
Each character in the sentence is encoded as a set of either 8 bits or 16 bits (international ASCII, known as UNICODE).
A set of 8 bits in sequence is called a byte.
Since writing in binary format is cumbersome, a different notation called Hexadecimal was introduced over time.
The same sequence in Hexadecimal becomes much more compact:
51756573746120467261736520747261646f74746120696e2062697420646976656e74657265626265The sentence occupies 41 bytes.
By the end, the book might take up around 700,000 characters/bytes, including spaces. However, this will depend on the encoding adopted in the publication format (e.g., EPUB, MOBI, KFD).
A keyboard encodes more than 256 characters, which is the maximum combination of 1s and 0s in 8 bits, because it must also encode special characters and various typographic forms (fonts in English).
To handle the encoding of special characters, such as those specific to different languages, a standard called Unicode was developed. Each character can be encoded with 8 up to 32 bits, meaning up to 4 bytes.
We refer to this as a multi-standard system because various methods of interpreting bits have emerged. Thankfully, these are converging into three main standards: UTF-8, UTF-16, and UTF-32.
Any type of information is considered data that is encoded into sequences of bytes through standards or rules.
We have understood that data can be represented as sequences of bits, which in computing terms are sometimes referred to as bit strings or byte strings (in this case, multiply the number by eight to get the byte count).
Just as there is a conversion table for computational power, there is one for bytes, which allows us to compactly represent large numbers:
- 1 kilobyte (KB) = 1,024 bytes
- 1 byte = 8 bits
- 1 gigabyte (GB) = 1,024 megabytes = 1,024 \u00d7 1,048,576 = 1,073,741,824 bytes
- 1 terabyte (TB) = 1,024 gigabytes
- 1 petabyte (PB) = 1,024 terabytes
- 1 megabyte (MB) = 1,024 kilobytes = 1,024 \u00d7 1,024 = 1,048,576 bytes
Now, when someone tells you that your smartphone has 1 GB of storage space, you’ll know it can hold 1,073,741,824 bytes or words, and you’ll also be able to compare it with other devices.
We’ve come to realize that all the information in an informational ecosystem can be represented as sequences of bits and interpreted through shared protocols and standards.
Could we enumerate them all?
If the ecosystem were static, perhaps yes, within a finite time.
Unfortunately, information in a digital ecosystem is constantly transforming; it is created, sometimes it disappears, it changes type while retaining meaning, and protocols and standards evolve. In fact, informational ecosystems struggle to eliminate information and tend to accumulate it, often for regulatory reasons.

Data storage
Where Are Data Stored? And With What Devices?
At the beginning of the history of computing, data were stored on paper. Yes, paper that was produced with holes, each corresponding to a 1.
Even the response was sometimes printed, including on punched tape.
I recall a scene from the British sci-fi series U.F.O., in which Commander Ed Straker (played by Ed Bishop) often read computer responses printed on sheets of paper.
Later, data storage transitioned to tape archives, used both for providing input to the computer and for saving information. During calculations, information was maintained in bit format by specific electrical devices, which initially were mechanical, then electromechanical (vacuum tubes), and eventually electronic (transistors).
In fact, the advent of the transistor was essential for both digital and analog electronics. Invented in 1947 by physicists John Bardeen, Walter Brattain, and William Shockley, it revolutionized technology and paved the way for the computer era.
Even today, one of the backup systems available is a magnetic tape device.
Given the high initial cost of maintaining data, a distinction was made between transient data and persistent data.
Persistent data refers to information that is not lost when the computer is powered off.
Nowadays, when we turn off one of our devices, it doesn’t fully shut down. To ensure a complete shutdown, we would have to remove all the onboard batteries and, in some cases, even the CPUs. However, in the early days, powering off the computer would result in the complete loss of all data.
Today, thanks to the high redundancy present at all stages of data transmission, losing data has become much less likely. Nevertheless, storing data persistently still incurs a significantly higher cost than storing it temporarily, and it also comes with the energy cost of keeping bits set to 1.
For this reason, our devices are equipped with two types of storage commonly referred to as RAM (Random Access Memory) and hard drives (Hard Disk, HD).
There are also write-once memories, such as ROMs (Read-Only Memory), which have near-zero energy maintenance costs.
RAM has limited storage space compared to hard drives.
Over the past 50 years, consumer-grade storage has evolved while adhering to this combinatory model.
New forms of storage have emerged, but they remain highly expensive and are reserved for niche scenarios.
The two storage modes address two primary needs and represent a trade-off: read/write speed and storage capacity.
Modern physical data storage technologies continuously innovate, employing different technologies with varying storage costs per byte.
Temporary storage systems are also referred to as short-term memory, while others are considered long-term memory.
Even long-term memory degrades over time. For data that needs to persist for more than a year, more robust solutions must be used to prevent wear. Unfortunately, these second-tier storage systems are significantly slower and more expensive per byte handled.
RAM has followed a development model similar to what Moore’s Law predicts, with steady improvements in performance and capacity.
Technologies like DDR (Double Data Rate) memory have increased speed and efficiency.
Recent innovations, such as 3D NAND and other advanced technologies, continue to enhance memory density and performance.
However, the rate of growth in RAM density is slowing as chip miniaturization approaches physical limits.
Emerging memory technologies, such as Phase-Change Memory (PCM) or Magnetoresistive RAM (MRAM), could provide alternative solutions to overcome these limitations.
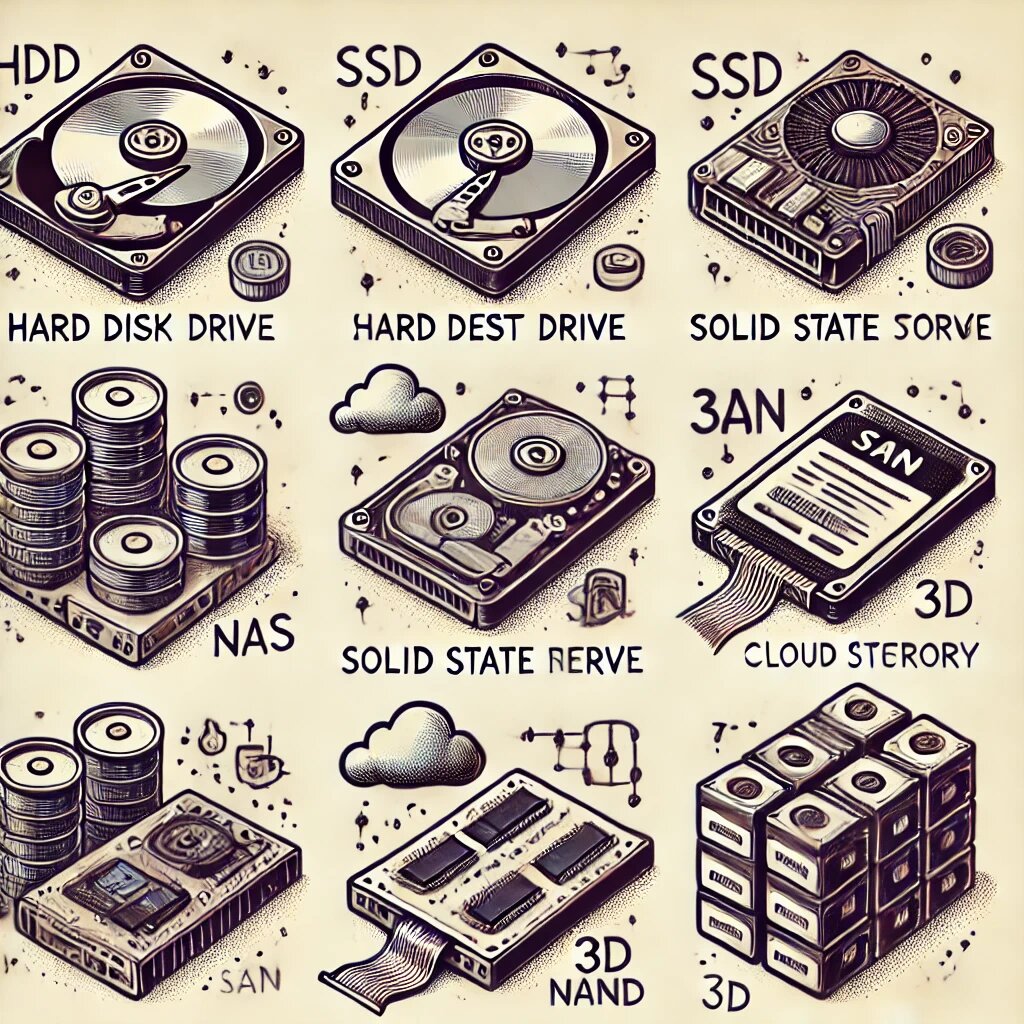
Table 3 – Data Storage Technologies provides an overview (not exhaustive) of the main technologies in use today for persistently storing data—our byte strings.
Table 3 – Data Storage Technologies
| Storage | Technology Name | Description | Characteristics | Usage |
|---|---|---|---|---|
| Local | HDD | Mechanical hard drives with rotating platters | Higher capacity for cost, slower than SSDs | Long-term storage, backups |
| Local | SSD | Solid-state drives based on flash memory | High speed, no moving parts, more expensive capacity | High-performance storage, used in computers and servers |
| Local | NAS | Network-connected storage device | Centralized, file sharing, easy to manage | Backup and file sharing for small and medium-sized businesses |
| Local | SAN | Network of storage devices connected via a dedicated network | High performance, scalable, more expensive and complex | Managing large volumes of data in large enterprises |
| Cloud | Public Cloud | Storage provided by third parties over the Internet | High scalability, remote access, pay-per-use model | Backup and globally accessible storage |
| Cloud | Private Cloud | Cloud infrastructure dedicated to a single organization | Greater control and security compared to public cloud | Storage for sensitive or regulated data |
| Local | Magnetic Tape | Technology that uses magnetic tapes for storage | Very low cost per byte, slow access time | Long-term storage with infrequent access |
| Local | 3D NAND Memory | Flash memory stacked vertically for greater capacity and performance | Higher density and performance compared to traditional NAND | High-end SSD storage for enhanced performance |
Table 4 – Wear Resistance of Storage Media
| Storage Technology | Speed | Security | Cost | Wear Resistance |
|---|---|---|---|---|
| HDD | 2 | 2 | 1 | 1 |
| SSD | 5 | 3 | 2 | 2 |
| NAS | 3 | 3 | 3 | 3 |
| SAN | 4 | 4 | 4 | 4 |
| Magnetic Tape | 1 | 4 | 4 | 5 |
Legend
Evaluation criteria range from 1 to 5, with 1 = low and 5 = high.
Storage technology can be chosen based on the storage objective, balancing characteristics such as speed, capacity, scalability, redundancy, and relative costs.
In an informational ecosystem, data continuously oscillate across many layers of the ISO/OSI stack. This results in logical and application-level differences in how our data are organized, even when using the same physical storage medium.
It’s important to consider that, apart from specialized informational systems, a typical system has a RAM capacity that is many factors smaller than its long-term storage capacity. Furthermore, persistent storage is even larger but significantly slower. This disparity is primarily due to production costs, which are tied to differing engineering approaches.
While the engineering of long-term storage devices is simpler—though still highly sophisticated—it is less expensive but bulkier compared to short-term memory devices.
Thus, short-term memory manages transient information, while long-term memory handles persistent information.
Where is this ebook information stored?
The information in my Book is likely stored on the same device you’re using to read it, in long-term memory. However, the page you’re currently reading is probably stored in short-term memory until you turn to the next or previous page.
The program you’re using to read it transfers sequences of bytes to the hardware (the graphics card), which displays them on your screen using a specific standard.
Over the years, models and algorithms have been developed to organize data in both short-term and long-term memory, aiming to address various user challenges. Writing data incurs a higher processing time cost (throughput) compared to reading it. This transfer cost is greater in long-term memory but also applies to high-speed short-term memory.
Even transferring data across the various buses of a motherboard has a cost, as does transmitting data through external communication channels of your device.
All information passes through communication channels that use different technologies but must still obey physical laws governing the transport of information. Bandwidth, latency, noise, and signal energy loss are the continuous challenges faced by electronic and telecommunications engineering.
These physical laws can be explained by comparing a data flow to a liquid flow. For instance, the capacity of a pipe indicates the maximum number of liters per second it can sustain. Under normal gravity and pressure conditions, this capacity cannot be exceeded. If the pipe is widened, turbulence may occur; if too many pipes are placed together, space constraints arise, and they cannot be infinite.
Additionally, if there isn’t enough stored potential energy, when you open the faucet, the water might not arrive immediately or in large quantities. This delay is analogous to bandwidth latency. A relatable example is when you return home after a long time away and reopen the main water valve (usually located near the water meter). It takes time for the water to reach the kitchen faucet if the valve is outside your house. This is an example of bandwidth latency.
If applied to your data packets (made of bytes), this means there’s a specific time it takes to reach you. If this time exceeds the rate at which you update the data, it leads to critical information loss.
This is why, for instance, a bank might build a cloud farm near its service center (and not the other way around). It’s also one of the main reasons to develop an entire cloud-native ecosystem, ensuring minimal latency even in multiregional architectures.
To save 1 GB of data from your smartphone onto another device will take time. This time depends on many factors, which, for better or worse, consistently affect the flow of information.
The cloud is designed to achieve better efficiency in transferring information compared to traditional ecosystems, but only if the data remains within the cloud itself.
Keep in mind that the cloud provider is contractually responsible for many of the key characteristics of data services: speed, preservation, high availability, etc. Depending on the service model you’ve purchased, you’ll receive guarantees with specific response times.
The cloud was born to manage data effectively and efficiently with a reduced Total Cost of Ownership (TCO), provided the data remains within the same cloud.
This is a crucial factor to consider in the adoption process.
The Emergence of Data Lakes
One of the cloud’s evolving strengths in recent years is the concept of a data lake.
If we think back to our chest-of-drawers example, it represents a data set modeled by its structure (drawers, levels, and types of clothing). For a long time, programmers developed algorithms aimed at addressing two different needs: fast data writing and fast data reading (especially recently written data).
Various algorithms have been created to make reading related data more efficient. It was discovered that efficient data reading depends on how related information is stored. This led to algorithms designed to store information about, for instance, the state of the chest at a given time, enabling fast querying of related data. These specialized algorithms operate on a data model guided by context.
Would the same algorithm work equally well in a different context, such as organizing a party? Over time, it was discovered that there is no universal algorithm that fits all scenarios, despite claims from advocates of one approach or another.
Here, we are essentially discussing the engines behind databases, algorithms initially developed to respond to specific software and hardware contexts that have since become de facto standards (much like binary encoding).
The cloud has changed this landscape, enabling a different approach. The data lake concept, which is applicable only in the cloud, promises to decouple data storage structures (the chest with socks and shirts) from the context, which is considered only during queries.
A data lake introduces an intermediary layer between the storage world and the world of searching and reading archived data.
Currently, this characterization of specific cloud resources is a specialization of a particular provider, raising concerns about vendor lock-in.
How response at lock-in challenge, in recent years, open solutions for data lake architectures have started to emerge. These aim to address the challenges of vendor lock-in by providing standardized, interoperable frameworks that allow organizations to build and manage data lakes across different cloud providers. Open data lake solutions promote portability, flexibility, and collaboration, enabling businesses to maintain control over their data while leveraging the benefits of a cloud-native approach.
It is essential to standardize and open up data lake architectures to ensure portability across different cloud providers.
I talk about the challenges in data lake adoption in a future post.
Human vs. AI Data Interpretation
A final consideration is the difference between human and AI-driven data interpretation.
For human users, structured information is essential, and data is often represented through abstractions such as pages, chapters, and formatted documents.
However, AI does not require these abstractions. Instead, AI processes data based on context and meaning rather than its visual or structural representation.
For example, a machine-learning model does not perceive a document in terms of pages and chapters—instead, it processes semantic relationships and extracts insights directly from unstructured data.The history of cloud computing offers a broad and detailed overview of the key milestones in the development of this technology. While not exhaustive, it provides an interpretation of innovation as a driving force
Holistic Vision
rom the very first spark of a voltage in a transistor to the massive architectures of today’s cloud-native ecosystems, data has always been the common thread. What begins as a simple binary choice—0 or 1—evolves through protocols, standards, and storage systems into the vast informational flows that power our world.
Encoding is not just a technical process: it is the language through which humans and machines agree to describe reality. From Shannon’s definition of the bit to ASCII and Unicode, to TCP/IP and the protocols that sustain the Internet, each layer of encoding adds meaning, reliability, and universality.
Storage, too, has mirrored our collective journey. From punched tape to RAM, SSDs, and data lakes, every new step has been driven by the need to preserve information, ensure resilience, and make it accessible at scale. The cloud amplifies this paradigm, reducing latency, lowering costs, and enabling organizations to build ecosystems where data does not merely survive but thrives as a living resource.
In this sense, encoding is more than a technical detail: it is the foundation of trust in digital ecosystems. Without a shared standard, communication collapses; without persistent storage, memory disappears; without scalable protocols, innovation stalls.
The holistic vision is clear:
Data encoding, storage, and transmission are not isolated layers of technology but interconnected dimensions of a single living ecosystem.
They enable organizations to transform raw signals into knowledge, knowledge into decisions, and decisions into actions.
Cloud-native ecosystems are the natural evolution of this continuum—where encoding is not static but adaptive, where storage expands dynamically, and where protocols evolve to keep pace with the complexity of human creativity and artificial intelligence.
Ultimately, to understand data encoding is to understand how we, as a society, give shape, order, and meaning to the information age.
References
This article is an excerpt from the book
Cloud-Native Ecosystems
A Living Link — Technology, Organization, and Innovation